This page presents a brief summary of some research and projects I have done to date, starting with newer work at the top.
Active Generation — Generative models for black box optimisation
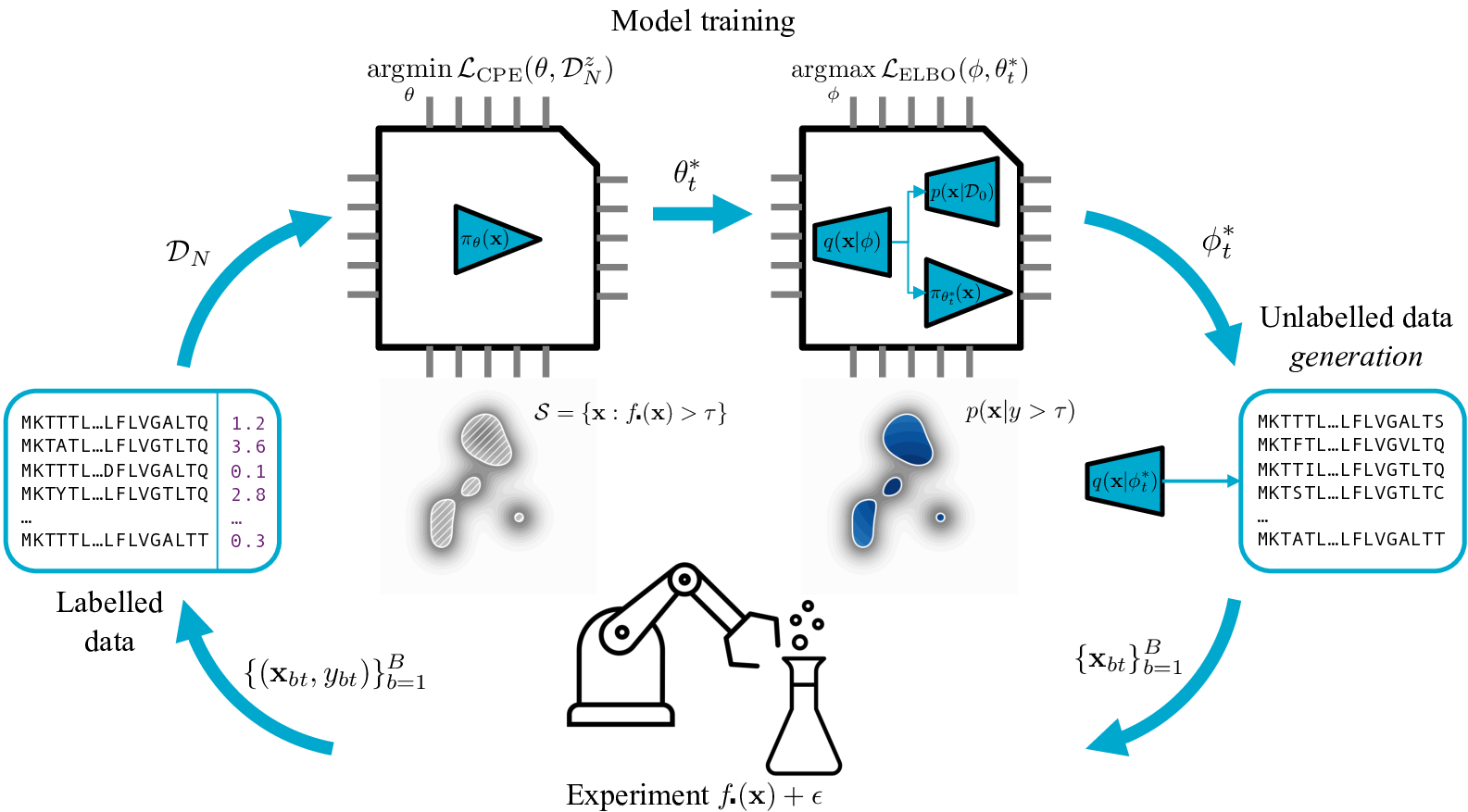
Active generation advances the union of generative modelling and black-box optimisation so that AI systems can design new artefacts — from molecules and materials to robotic components and algorithms — directly from high-level objectives. We combine powerful generative priors with machine-learning optimisation loops to turn expensive design problems into targeted, data-driven discovery pipelines.
Causal Discovery in the Real World — DAG estimation under realistic conditions
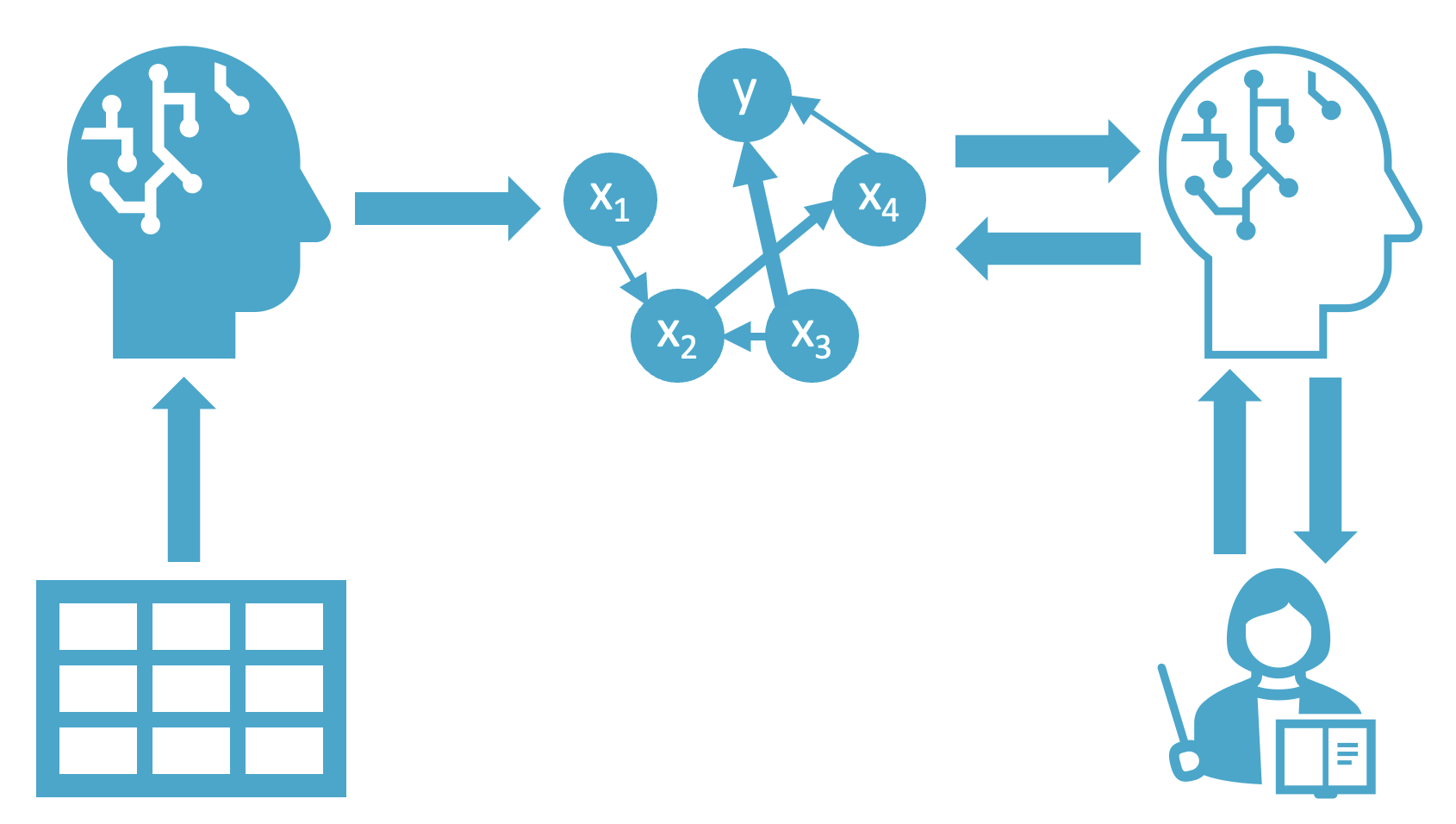
Inferring causal structure from observational data is hard: real data violates the clean assumptions most methods require. CaPE brings an expert into the loop with a Bayesian active learning framework that strategically queries edge relationships in the graph to resolve ambiguity. Arrow is a transformer-based foundation model that performs zero-shot causal discovery on new tabular datasets with no task-specific training required.
Causal Inference — Machine learning for evidence-based policy
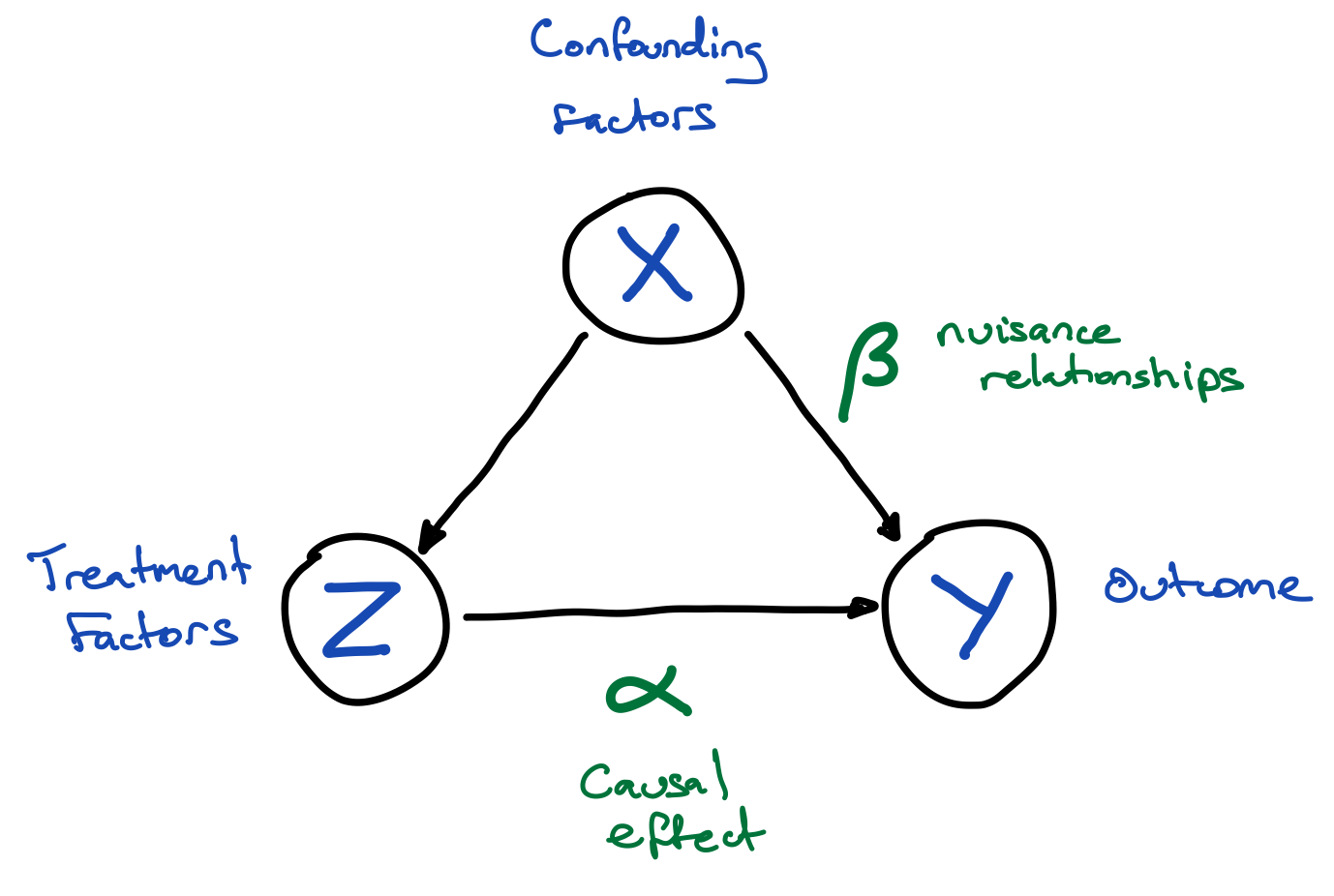
Machine learning can help capture complex relationships in observational data, mitigating bias from model mis-specification in causal inference studies — a cornerstone of evidence-based policy. We have applied these methods to linking youth well-being to academic success, and developed open-source tooling for reporting non-linear causal effects.
Algorithmic Fairness — Fair regression algorithms
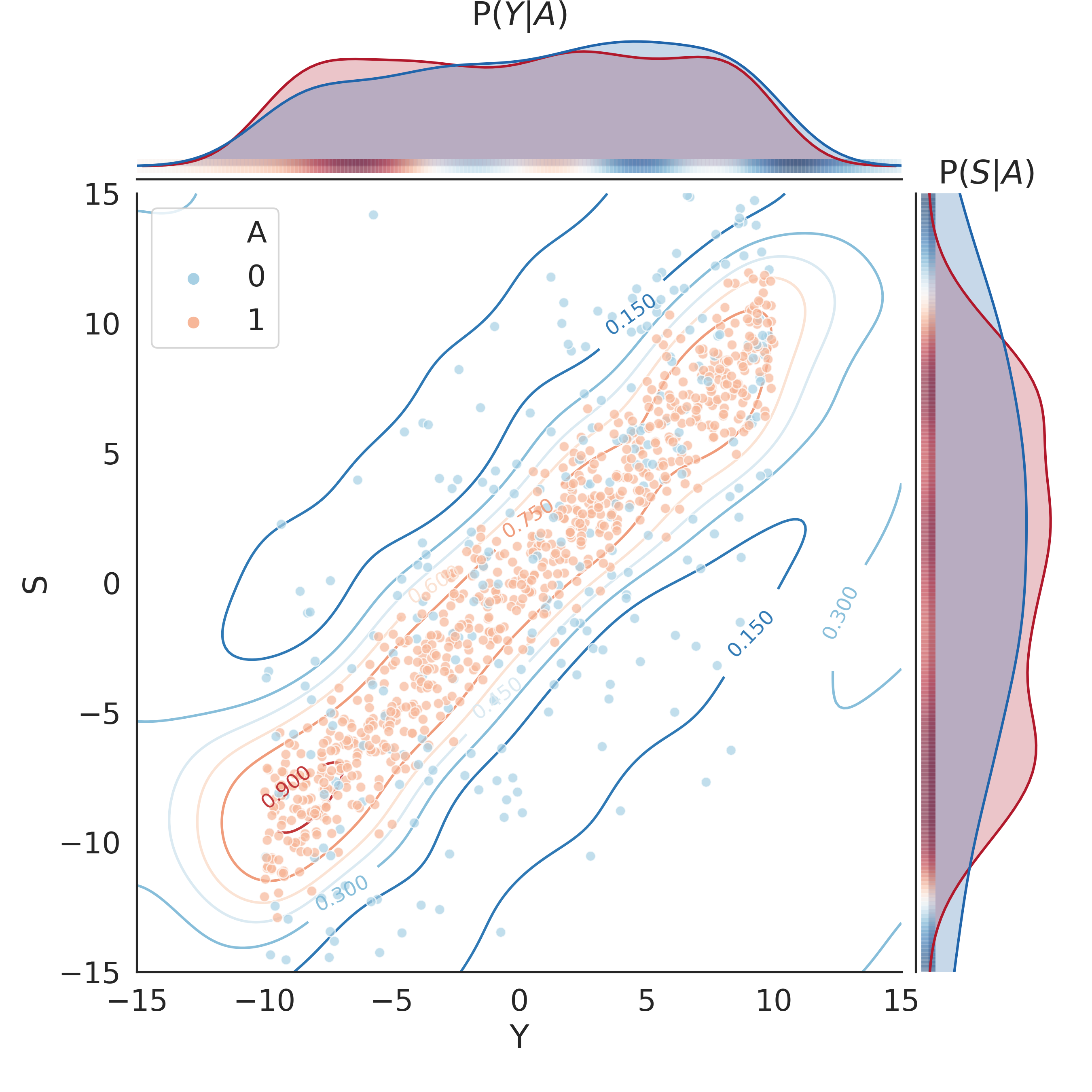
Algorithmic fairness involves expressing notions such as equity and equality as quantifiable measures that a machine learning algorithm can optimise. My research at Gradient Institute has targeted the regression setting, where measuring and adjusting for fairness is substantially harder than in the classification case.
Landshark — Large-scale spatial inference with TensorFlow
Landshark is a set of Python command-line tools for supervised learning on large spatial raster datasets, targeting the case where training data does not fit in memory. It uses TensorFlow and minibatch stochastic gradient descent to scale to very large covariate images, such as satellite imagery or geophysics.
Aboleth — A TensorFlow framework for Bayesian deep learning
Aboleth is a bare-bones TensorFlow framework for Bayesian deep learning and Gaussian process approximation. It provides high-performance, lightweight components for building Bayesian neural nets and approximate deep Gaussian process computational graphs, with minimal abstraction over pure TensorFlow.
Revrand — Scalable Bayesian generalised linear models

Revrand is a software library implementing Bayesian linear models and generalised linear models. It uses random kitchen sink basis functions to approximate Gaussian processes with linear models, and nonparametric variational inference for non-Gaussian likelihoods — all with large-scale stochastic gradient learning.
Extended and Unscented Kitchen Sinks
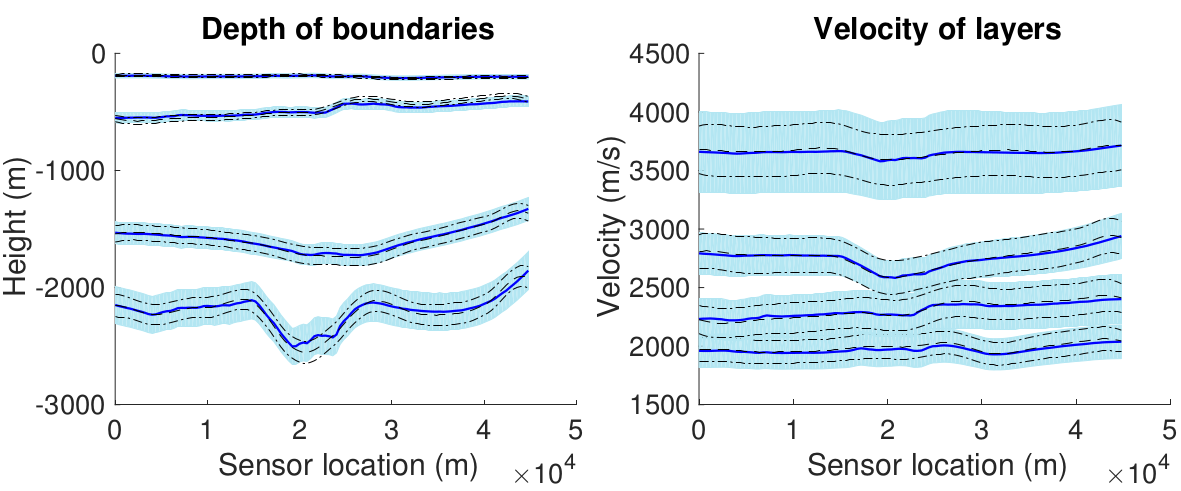
An extension of the unscented and extended Gaussian processes to multiple outputs and large datasets, using the random kitchen sink basis function approximation for scalability. These algorithms are applicable to a wide variety of complex nonlinear inversion problems, such as geophysical inversions.
Job Automation Impact — The impact of computerisation on Australian employment
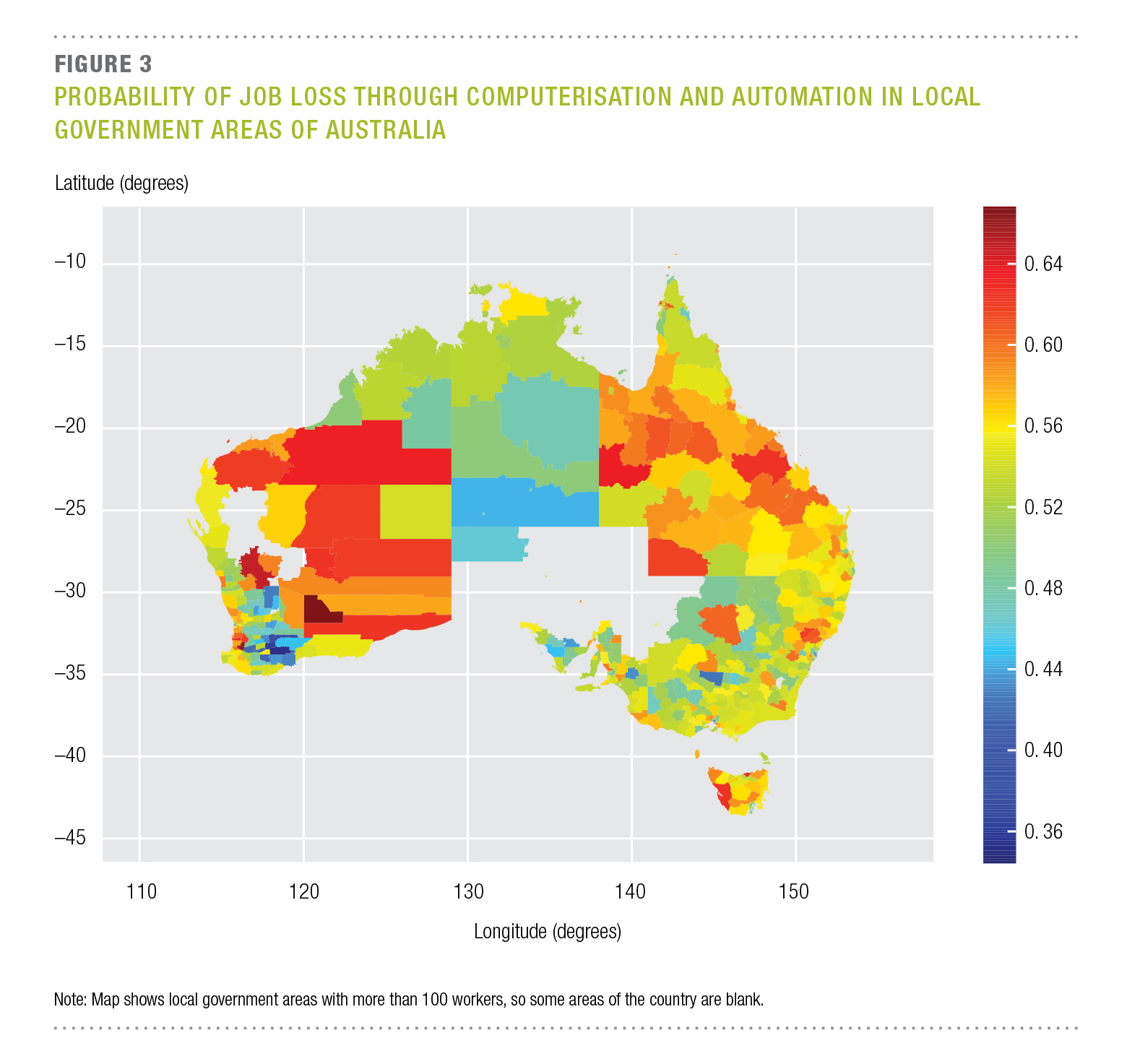
A qualitative study into the susceptibility of jobs in Australia to computerisation and automation over 10–15 years, following the methodology of Frey and Osborne. Results show 40% of Australian jobs have a high probability of being susceptible, with administration and mining regions most at risk.
Nonparametric Bayesian Inverse Problems
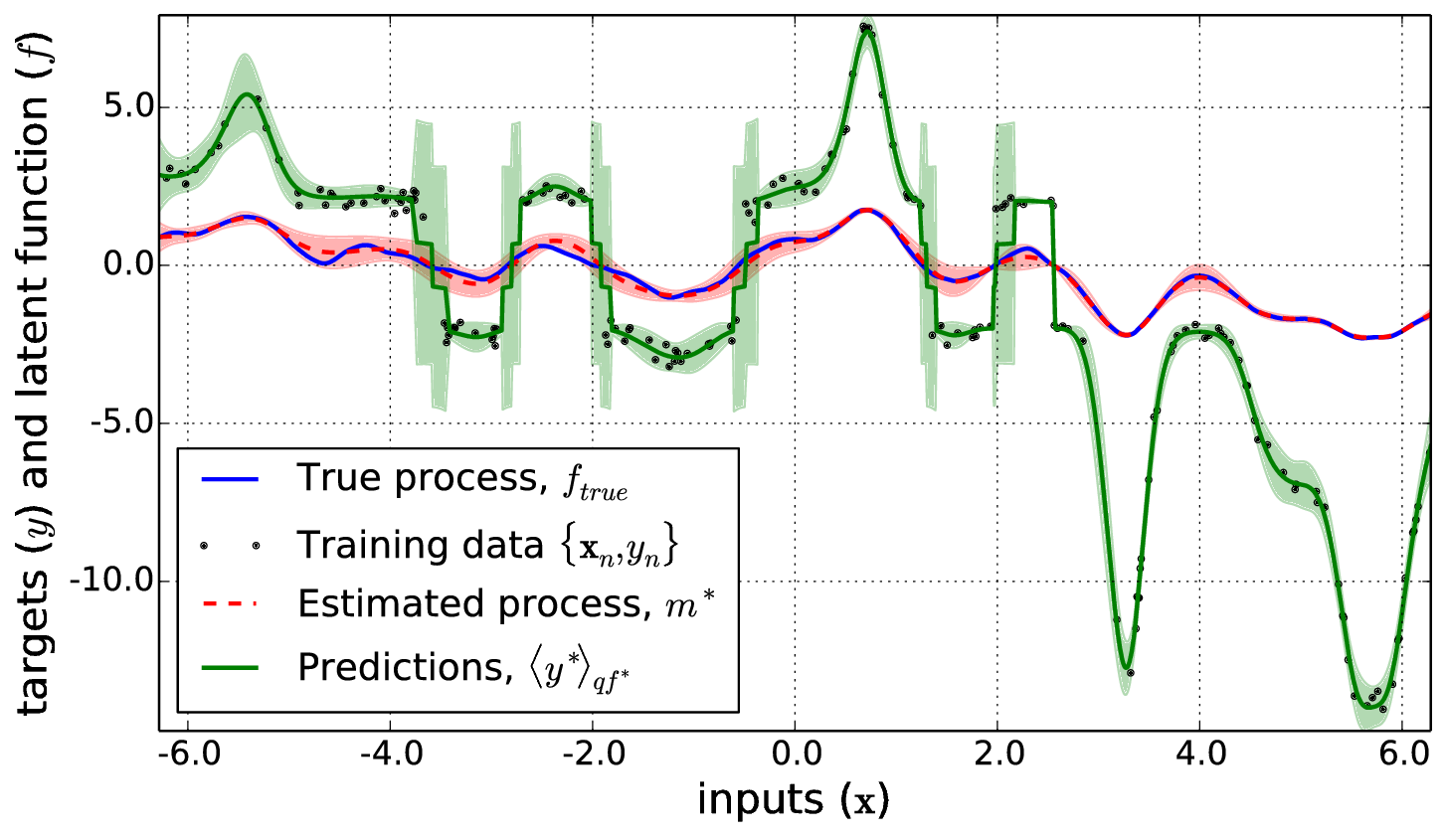
Two new methods for inference in Gaussian process models with general nonlinear likelihoods — the extended and unscented GPs. Based on a variational framework, these algorithms are equivalent to iterative extended and unscented Kalman filter updates, and the unscented variant handles non-differentiable likelihoods as a black box. Presented as a NIPS spotlight paper.
Unsupervised Scene Understanding

Algorithms that simultaneously cluster images and segments (super-pixels), modelling context by jointly representing scenes by whole-image descriptors and the distribution of objects within them. These methods outperform other unsupervised approaches and are competitive with supervised methods, while scaling to large datasets.
Clustering Images Over Many Datasets
A latent Dirichlet allocation-like algorithm that shares image clusters across related collections (e.g., photo albums) while keeping mixture weights specific to each group. This context modelling yields more self-consistent clusters and is often faster than standard mixture models on large datasets.
Clustering Images of the Seafloor

Application of a variational Dirichlet process to unsupervised clustering of large-scale seafloor imagery from autonomous underwater vehicles. The non-parametric approach requires no knowledge of the number of clusters, producing habitat-type clusters useful for spatial pattern analysis and adaptive sampling.
